{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.7"
},
"colab": {
"name": "Huggingface_transformers.ipynb",
"provenance": [],
"collapsed_sections": []
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "sjB68KGLb26k",
"colab_type": "text"
},
"source": [
"## 利用[Huggingface](https://huggingface.co/transformers/installation.html#)实现的预训练语言模型做下游任务\n",
"by Qiao for NLP7 2020-8-16\n",
"\n",
"预训练语言模型的用法:\n",
"1. 作为特征提取器\n",
"2. 作为encoder参与下游任务微调\n",
"使用上非常类似,差别是后者在训练过程中原预训练语言模型的参数也允许优化。\n",
"\n",
"主要内容:\n",
"1. 以XLNet介绍HuggingFace transformers组件的使用套路\n",
"2. 以XLNet为例介绍如何接续下游的文本分类和抽取式问答。\n",
"\n",
"主要参考[文档](https://huggingface.co/transformers/model_doc/xlnet.html)和[代码](https://github.com/huggingface/transformers/blob/0ed7c00ba6b3178c8c323a0440bf1221fb99784b/src/transformers/modeling_xlnet.py)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0dw21tvyb26k",
"colab_type": "text"
},
"source": [
"### 以[XLNet](https://huggingface.co/transformers/model_doc/xlnet.html)为例,使用其他Huggingface封装的预训练语言模型的套路与类似"
]
},
{
"cell_type": "code",
"metadata": {
"id": "mD69bu-ib26l",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 336
},
"outputId": "211897cc-436e-4f63-f903-05915e498cd9"
},
"source": [
"import os\n",
"import torch\n",
"import torch.nn as nn\n",
"import torch.functional as F\n",
"!pip install transformers\n",
"from transformers import XLNetModel, XLNetTokenizer, XLNetConfig"
],
"execution_count": 1,
"outputs": [
{
"output_type": "stream",
"text": [
"Requirement already satisfied: transformers in /usr/local/lib/python3.6/dist-packages (3.0.2)\n",
"Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.6/dist-packages (from transformers) (2019.12.20)\n",
"Requirement already satisfied: tokenizers==0.8.1.rc1 in /usr/local/lib/python3.6/dist-packages (from transformers) (0.8.1rc1)\n",
"Requirement already satisfied: requests in /usr/local/lib/python3.6/dist-packages (from transformers) (2.23.0)\n",
"Requirement already satisfied: dataclasses; python_version < \"3.7\" in /usr/local/lib/python3.6/dist-packages (from transformers) (0.7)\n",
"Requirement already satisfied: filelock in /usr/local/lib/python3.6/dist-packages (from transformers) (3.0.12)\n",
"Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.6/dist-packages (from transformers) (4.41.1)\n",
"Requirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from transformers) (1.18.5)\n",
"Requirement already satisfied: sacremoses in /usr/local/lib/python3.6/dist-packages (from transformers) (0.0.43)\n",
"Requirement already satisfied: packaging in /usr/local/lib/python3.6/dist-packages (from transformers) (20.4)\n",
"Requirement already satisfied: sentencepiece!=0.1.92 in /usr/local/lib/python3.6/dist-packages (from transformers) (0.1.91)\n",
"Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests->transformers) (2020.6.20)\n",
"Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests->transformers) (1.24.3)\n",
"Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->transformers) (2.10)\n",
"Requirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->transformers) (3.0.4)\n",
"Requirement already satisfied: joblib in /usr/local/lib/python3.6/dist-packages (from sacremoses->transformers) (0.16.0)\n",
"Requirement already satisfied: click in /usr/local/lib/python3.6/dist-packages (from sacremoses->transformers) (7.1.2)\n",
"Requirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from sacremoses->transformers) (1.15.0)\n",
"Requirement already satisfied: pyparsing>=2.0.2 in /usr/local/lib/python3.6/dist-packages (from packaging->transformers) (2.4.7)\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "XDPX4oSouZHa",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 34
},
"outputId": "3c1a1a3c-1064-4f10-e889-71b031aafa43"
},
"source": [
"torch.transpose(torch.ones((3,2,4)), 2, 1).shape"
],
"execution_count": 2,
"outputs": [
{
"output_type": "execute_result",
"data": {
"text/plain": [
"torch.Size([3, 4, 2])"
]
},
"metadata": {
"tags": []
},
"execution_count": 2
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "8Hf6yUBab26n",
"colab_type": "code",
"colab": {}
},
"source": [
"tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')\n",
"model = XLNetModel.from_pretrained('xlnet-base-cased', \n",
" output_hidden_states=True,\n",
" output_attentions=True)"
],
"execution_count": 3,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "eA4TQ7Xnb26p",
"colab_type": "text"
},
"source": [
"### 注意:\n",
"以上使用模型名称初始化的模块,程序会在后台下载预训练完成的XLNet模型并加载。对于内地同学,除改变上网方式外,还可以手动下载模型,指定路径加载。\n",
"#### 手动下载模型:\n",
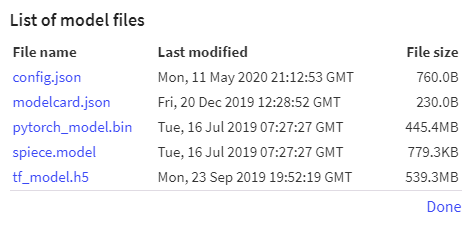
"在HuggingFace官方[模型库](https://huggingface.co/models)上找到需要下载的模型,点击模型链接,例如:[xlnet-base-cased](https://huggingface.co/xlnet-base-cased)模型。在跳转到的模型页面中点击`List all files in model`(字比较小,注意查看),将跳出框中的模型相关文(pytorch或tf版本)件保存到本地。\n",
""
]
},
{
"cell_type": "code",
"metadata": {
"id": "XSoaGwNlb26q",
"colab_type": "code",
"colab": {}
},
"source": [
"# # 本地加载XLNet模型\n",
"# MODEL_PATH = r\"D:\\data\\nlp\\xlnet-model/\"\n",
"# config = XLNetConfig.from_json_file(os.path.join(MODEL_PATH, \"xlnet-base-cased-config.json\"))\n",
"\n",
"# #config文件不仅用于设置模型参数,也可以用来控制模型的行为\n",
"# config.output_hidden_states = True\n",
"# config.output_attentions = True\n",
"\n",
"# tokenizer = XLNetTokenizer(os.path.join(MODEL_PATH, 'xlnet-base-cased-spiece.model'))\n",
"# model = XLNetModel.from_pretrained(MODEL_PATH, config = config)"
],
"execution_count": 4,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "SwIhUM-gb26r",
"colab_type": "text"
},
"source": [
"### 1. 句子到token id转换"
]
},
{
"cell_type": "code",
"metadata": {
"id": "BF5mo_D5b26s",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 67
},
"outputId": "3d16e75b-3a6e-4795-d2b4-54c6668ea1aa"
},
"source": [
"# 利用tokenizer将原始的句子准备成模型输入\n",
"sentence = \"This is an interesting review session\"\n",
"\n",
"# tokenization\n",
"tokens = tokenizer.tokenize(sentence)\n",
"print(\"Tokens: {}\".format(tokens))\n",
"\n",
"# 将token转化为ID\n",
"tokens_ids = tokenizer.convert_tokens_to_ids(tokens)\n",
"print(\"Tokens id: {}\".format(tokens_ids))\n",
"\n",
"# 添加特殊token: <cls>, <sep>\n",
"tokens_ids = tokenizer.build_inputs_with_special_tokens(tokens_ids)\n",
"\n",
"# 准备成pytorch tensor\n",
"tokens_pt = torch.tensor([tokens_ids])\n",
"print(\"Tokens PyTorch: {}\".format(tokens_pt))\n",
"\n",
"# print(tokenizer.convert_ids_to_tokens([122, 27, 48, 5272, 717, 4, 3]))\n"
],
"execution_count": 5,
"outputs": [
{
"output_type": "stream",
"text": [
"Tokens: ['▁This', '▁is', '▁an', '▁interesting', '▁review', '▁session']\n",
"Tokens id: [122, 27, 48, 2456, 1398, 1961]\n",
"Tokens PyTorch: tensor([[ 122, 27, 48, 2456, 1398, 1961, 4, 3]])\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "qqhXQD9pb26u",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 54
},
"outputId": "9fa8afcc-00ea-427a-a065-60467c49c201"
},
"source": [
"# 偷懒的一条龙服务\n",
"tokens_pt2 = tokenizer(sentence, return_tensors=\"pt\")\n",
"print(\"Tokens PyTorch: {}\".format(tokens_pt2))"
],
"execution_count": 6,
"outputs": [
{
"output_type": "stream",
"text": [
"Tokens PyTorch: {'input_ids': tensor([[ 122, 27, 48, 2456, 1398, 1961, 4, 3]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 2]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "9rN4h6CFb26w",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 84
},
"outputId": "72ce2de4-4614-4301-9903-349483cd3863"
},
"source": [
"# 批处理\n",
"# padding\n",
"sentences = [\"The ultimate answer to life, universe and time is 42.\", \"Take a towel for a space travel.\"]\n",
"print(\"Batch tokenization:\\n\", tokenizer(sentences)['input_ids'])\n",
"print(\"With Padding:\\n\", tokenizer(sentences, padding=True)['input_ids'])"
],
"execution_count": 7,
"outputs": [
{
"output_type": "stream",
"text": [
"Batch tokenization:\n",
" [[32, 6452, 1543, 22, 235, 19, 6486, 21, 92, 27, 4087, 9, 4, 3], [3636, 24, 14680, 28, 24, 888, 1316, 9, 4, 3]]\n",
"With Padding:\n",
" [[32, 6452, 1543, 22, 235, 19, 6486, 21, 92, 27, 4087, 9, 4, 3], [5, 5, 5, 5, 3636, 24, 14680, 28, 24, 888, 1316, 9, 4, 3]]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "hNv9Hw8Mb26y",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 67
},
"outputId": "517d90c7-2a8f-46c9-f48f-8da0cb415e0e"
},
"source": [
"# 输入句子对:\n",
"multi_seg_input = tokenizer(\"This is segment A\", \"This is segment B\")\n",
"print(\"Multi segment token (str): {}\".format(tokenizer.convert_ids_to_tokens(multi_seg_input['input_ids'])))\n",
"print(\"Multi segment token (int): {}\".format(multi_seg_input['input_ids']))\n",
"print(\"Multi segment type : {}\".format(multi_seg_input['token_type_ids']))"
],
"execution_count": 8,
"outputs": [
{
"output_type": "stream",
"text": [
"Multi segment token (str): ['▁This', '▁is', '▁segment', '▁A', '<sep>', '▁This', '▁is', '▁segment', '▁B', '<sep>', '<cls>']\n",
"Multi segment token (int): [122, 27, 7295, 79, 4, 122, 27, 7295, 322, 4, 3]\n",
"Multi segment type : [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2]\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "KfjZ9f_wb260",
"colab_type": "text"
},
"source": [
"### 2. 模型encoding"
]
},
{
"cell_type": "code",
"metadata": {
"id": "lxzgyb5jb260",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 84
},
"outputId": "a3806e2d-7d7c-4e7a-99d8-e846b4618315"
},
"source": [
"# 默认情况下,model.dev()模式下。下面使用模型Encode输入的句子\n",
"# 因为我们在config中设置模型返回每层的hidden states和注意力,再加上默认输出的最后一层隐状态,输出有3个部分\n",
"print(\"Is training mode ? \", model.training)\n",
"\n",
"sentence = \"The ultimate answer to life, universe and time is 42.\"\n",
"\n",
"tokens_pt = tokenizer(sentence, return_tensors=\"pt\")\n",
"print(\"Token (str): {}\".format(\n",
" tokenizer.convert_ids_to_tokens(tokens_pt['input_ids'][0])\n",
" ))\n",
"\n",
"final_layer_h, all_layer_h, attentions = model(**tokens_pt)\n",
"\n",
"print(torch.sum(final_layer_h - all_layer_h[-1]).item())\n",
"\n",
"final_layer_h.shape, len(all_layer_h), len(attentions)"
],
"execution_count": 9,
"outputs": [
{
"output_type": "stream",
"text": [
"Is training mode ? False\n",
"Token (str): ['▁The', '▁ultimate', '▁answer', '▁to', '▁life', ',', '▁universe', '▁and', '▁time', '▁is', '▁42', '.', '<sep>', '<cls>']\n",
"0.0\n"
],
"name": "stdout"
},
{
"output_type": "execute_result",
"data": {
"text/plain": [
"(torch.Size([1, 14, 768]), 13, 12)"
]
},
"metadata": {
"tags": []
},
"execution_count": 9
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "QbV9RUCcb262",
"colab_type": "text"
},
"source": [
"### 3. 下游任务\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fDuKbswbb263",
"colab_type": "text"
},
"source": [
"### 例1. 文本分类"
]
},
{
"cell_type": "code",
"metadata": {
"id": "t8Hl4iFib263",
"colab_type": "code",
"colab": {}
},
"source": [
"class XLNetSeqSummary(nn.Module):\n",
" \n",
" def __init__(self, \n",
" how='cls', \n",
" hidden_size=768, \n",
" activation=None, \n",
" first_dropout=None, \n",
" last_dropout=None):\n",
" super().__init__()\n",
" self.how = how\n",
" self.summary = nn.Linear(hidden_size, hidden_size)\n",
" self.activation = activation if activation else nn.GELU()\n",
" self.first_dropout = first_dropout if first_dropout else nn.Dropout(0.5)\n",
" self.last_dropout = last_dropout if last_dropout else nn.Dropout(0.5)\n",
"\n",
" def forward(self, hidden_states):\n",
" \"\"\"\n",
" 对隐状态序列池化或返回cls处的表示,作为句子的encoding\n",
" Args:\n",
" hidden_states :\n",
" XLNet模型输出的最后层隐状态序列.\n",
" Returns:\n",
" : 句子向量表示\n",
" \"\"\"\n",
" if self.how == \"cls\":\n",
" output = hidden_states[:, -1]\n",
" elif self.how == \"mean\":\n",
" output = hidden_states.mean(dim=1)\n",
" elif self.how == \"max\":\n",
" output = hidden_states.max(dim=1)\n",
" else:\n",
" raise Exception(\"Summary type '{}' not implemted.\".format(self.how))\n",
"\n",
" output = self.first_dropout(output)\n",
" output = self.summary(output)\n",
" output = self.activation(output)\n",
" output = self.last_dropout(output)\n",
"\n",
" return output\n",
"\n",
"\n",
"class XLNetSentenceClassifier(nn.Module):\n",
" \n",
" def __init__(self,\n",
" num_labels,\n",
" xlnet_model,\n",
" d_model=768):\n",
" super().__init__()\n",
" self.num_labels = num_labels\n",
" self.d_model = d_model\n",
" self.transformer = xlnet_model\n",
" self.sequence_summary = XLNetSeqSummary('cls', d_model, nn.GELU())\n",
" self.logits_proj = nn.Linear(d_model, num_labels)\n",
" \n",
" def forward(self, model_inputs):\n",
" transformer_outputs = self.transformer(**model_inputs)\n",
" \n",
" output = transformer_outputs[0]\n",
" output = self.sequence_summary(output)\n",
" logits = self.logits_proj(output)\n",
"\n",
" return logits\n",
" \n",
"def get_loss(criterion, logits, labels):\n",
" return criterion(logits, labels)\n",
"\n"
],
"execution_count": 10,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "wvLk2n2s11dm",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 1000
},
"outputId": "52126a88-3eb9-43b0-a9b1-b1ee3fe0d7a9"
},
"source": [
"# 验证forward和反向传播\n",
"\n",
"# toy examples\n",
"sentences = [\"The ultimate answer to life, universe and time is 42.\", \n",
" \"Take a towel for a space travel.\"]\n",
"labels = torch.LongTensor([0, 1])\n",
"\n",
"# 实例化各个模块\n",
"criterion = nn.CrossEntropyLoss()\n",
"classifier = XLNetSentenceClassifier(2, model, 768)\n",
"optimizer = torch.optim.AdamW(classifier.parameters())\n",
"\n",
"# forward + loss\n",
"classifier.train()\n",
"optimizer.zero_grad()\n",
"logits = classifier(tokenizer(sentences, padding=True, return_tensors='pt'))\n",
"loss = get_loss(criterion, logits, labels)\n",
"\n",
"print(\"Loss: \", loss.item())\n",
"\n",
"# backwawrd step\n",
"loss.backward()\n",
"optimizer.step()\n",
"\n",
"print(\"=\"*25)\n",
"print(\"Confirm that the gradients are computed for the original XLNet parameters.\\n\")\n",
"print(\"=\"*25)\n",
"for param in classifier.parameters():\n",
" print(param.shape, param.grad.sum() if not param.grad is None else param.grad)"
],
"execution_count": 11,
"outputs": [
{
"output_type": "stream",
"text": [
"/usr/local/lib/python3.6/dist-packages/transformers/modeling_xlnet.py:283: UserWarning: Mixed memory format inputs detected while calling the operator. The operator will output contiguous tensor even if some of the inputs are in channels_last format. (Triggered internally at /pytorch/aten/src/ATen/native/TensorIterator.cpp:918.)\n",
" attn_score = (ac + bd + ef) * self.scale\n"
],
"name": "stderr"
},
{
"output_type": "stream",
"text": [
"Loss: 3.1768088340759277\n",
"=========================\n",
"Confirm that the gradients are computed for the original XLNet parameters.\n",
"\n",
"=========================\n",
"torch.Size([1, 1, 768]) None\n",
"torch.Size([32000, 768]) tensor(25.7372)\n",
"torch.Size([768, 12, 64]) tensor(-1.2605)\n",
"torch.Size([768, 12, 64]) tensor(-0.0260)\n",
"torch.Size([768, 12, 64]) tensor(-28.2512)\n",
"torch.Size([768, 12, 64]) tensor(-5.9904)\n",
"torch.Size([768, 12, 64]) tensor(-16.8508)\n",
"torch.Size([12, 64]) tensor(2.1390)\n",
"torch.Size([12, 64]) tensor(-0.4672)\n",
"torch.Size([12, 64]) tensor(-0.0809)\n",
"torch.Size([2, 12, 64]) tensor(-2.3341e-08)\n",
"torch.Size([768]) tensor(-2.5859)\n",
"torch.Size([768]) tensor(0.7296)\n",
"torch.Size([768]) tensor(27.5062)\n",
"torch.Size([768]) tensor(0.6071)\n",
"torch.Size([3072, 768]) tensor(31.7035)\n",
"torch.Size([3072]) tensor(-2.4280)\n",
"torch.Size([768, 3072]) tensor(-35.7826)\n",
"torch.Size([768]) tensor(1.0238)\n",
"torch.Size([768, 12, 64]) tensor(-17.0880)\n",
"torch.Size([768, 12, 64]) tensor(19.3293)\n",
"torch.Size([768, 12, 64]) tensor(-47.9725)\n",
"torch.Size([768, 12, 64]) tensor(-13.6990)\n",
"torch.Size([768, 12, 64]) tensor(58.4259)\n",
"torch.Size([12, 64]) tensor(-0.6855)\n",
"torch.Size([12, 64]) tensor(-0.0564)\n",
"torch.Size([12, 64]) tensor(1.0304)\n",
"torch.Size([2, 12, 64]) tensor(-2.8708e-07)\n",
"torch.Size([768]) tensor(9.0300)\n",
"torch.Size([768]) tensor(-1.0958)\n",
"torch.Size([768]) tensor(5.4917)\n",
"torch.Size([768]) tensor(22.9240)\n",
"torch.Size([3072, 768]) tensor(115.8651)\n",
"torch.Size([3072]) tensor(5.3853)\n",
"torch.Size([768, 3072]) tensor(-255.6405)\n",
"torch.Size([768]) tensor(1.5782)\n",
"torch.Size([768, 12, 64]) tensor(4.2417)\n",
"torch.Size([768, 12, 64]) tensor(-14.8971)\n",
"torch.Size([768, 12, 64]) tensor(-73.9943)\n",
"torch.Size([768, 12, 64]) tensor(46.1016)\n",
"torch.Size([768, 12, 64]) tensor(-90.2583)\n",
"torch.Size([12, 64]) tensor(-0.7491)\n",
"torch.Size([12, 64]) tensor(-0.0379)\n",
"torch.Size([12, 64]) tensor(2.2957)\n",
"torch.Size([2, 12, 64]) tensor(-1.3356e-07)\n",
"torch.Size([768]) tensor(3.8442)\n",
"torch.Size([768]) tensor(-0.0809)\n",
"torch.Size([768]) tensor(-11.6207)\n",
"torch.Size([768]) tensor(-0.3207)\n",
"torch.Size([3072, 768]) tensor(-19.1237)\n",
"torch.Size([3072]) tensor(-1.3429)\n",
"torch.Size([768, 3072]) tensor(-289.4715)\n",
"torch.Size([768]) tensor(2.3313)\n",
"torch.Size([768, 12, 64]) tensor(-10.7058)\n",
"torch.Size([768, 12, 64]) tensor(1.4629)\n",
"torch.Size([768, 12, 64]) tensor(-2.1070)\n",
"torch.Size([768, 12, 64]) tensor(-6.4306)\n",
"torch.Size([768, 12, 64]) tensor(27.9962)\n",
"torch.Size([12, 64]) tensor(0.3387)\n",
"torch.Size([12, 64]) tensor(0.0497)\n",
"torch.Size([12, 64]) tensor(1.1483)\n",
"torch.Size([2, 12, 64]) tensor(-5.8644e-08)\n",
"torch.Size([768]) tensor(-2.1899)\n",
"torch.Size([768]) tensor(2.6034)\n",
"torch.Size([768]) tensor(-7.3790)\n",
"torch.Size([768]) tensor(57.4574)\n",
"torch.Size([3072, 768]) tensor(20.5142)\n",
"torch.Size([3072]) tensor(-0.6371)\n",
"torch.Size([768, 3072]) tensor(-376.4980)\n",
"torch.Size([768]) tensor(2.2438)\n",
"torch.Size([768, 12, 64]) tensor(4.6743)\n",
"torch.Size([768, 12, 64]) tensor(2.6259)\n",
"torch.Size([768, 12, 64]) tensor(61.2118)\n",
"torch.Size([768, 12, 64]) tensor(-19.2858)\n",
"torch.Size([768, 12, 64]) tensor(-51.2790)\n",
"torch.Size([12, 64]) tensor(-0.8702)\n",
"torch.Size([12, 64]) tensor(0.0449)\n",
"torch.Size([12, 64]) tensor(0.8889)\n",
"torch.Size([2, 12, 64]) tensor(-8.0654e-09)\n",
"torch.Size([768]) tensor(5.7260)\n",
"torch.Size([768]) tensor(0.1210)\n",
"torch.Size([768]) tensor(-2.8192)\n",
"torch.Size([768]) tensor(2.0098)\n",
"torch.Size([3072, 768]) tensor(21.2937)\n",
"torch.Size([3072]) tensor(-1.0464)\n",
"torch.Size([768, 3072]) tensor(64.5268)\n",
"torch.Size([768]) tensor(-0.4186)\n",
"torch.Size([768, 12, 64]) tensor(-9.6220)\n",
"torch.Size([768, 12, 64]) tensor(-1.0370)\n",
"torch.Size([768, 12, 64]) tensor(-37.3973)\n",
"torch.Size([768, 12, 64]) tensor(6.7878)\n",
"torch.Size([768, 12, 64]) tensor(-25.5568)\n",
"torch.Size([12, 64]) tensor(0.2431)\n",
"torch.Size([12, 64]) tensor(-0.0594)\n",
"torch.Size([12, 64]) tensor(0.5624)\n",
"torch.Size([2, 12, 64]) tensor(1.2550e-07)\n",
"torch.Size([768]) tensor(1.9311)\n",
"torch.Size([768]) tensor(4.0691)\n",
"torch.Size([768]) tensor(-0.2573)\n",
"torch.Size([768]) tensor(-2.1677)\n",
"torch.Size([3072, 768]) tensor(33.1953)\n",
"torch.Size([3072]) tensor(-1.2758)\n",
"torch.Size([768, 3072]) tensor(48.7794)\n",
"torch.Size([768]) tensor(-0.3968)\n",
"torch.Size([768, 12, 64]) tensor(47.0431)\n",
"torch.Size([768, 12, 64]) tensor(-0.2368)\n",
"torch.Size([768, 12, 64]) tensor(-44.1680)\n",
"torch.Size([768, 12, 64]) tensor(0.6996)\n",
"torch.Size([768, 12, 64]) tensor(48.9892)\n",
"torch.Size([12, 64]) tensor(-1.2048)\n",
"torch.Size([12, 64]) tensor(0.0624)\n",
"torch.Size([12, 64]) tensor(-0.2197)\n",
"torch.Size([2, 12, 64]) tensor(4.6683e-08)\n",
"torch.Size([768]) tensor(-0.7691)\n",
"torch.Size([768]) tensor(-1.1337)\n",
"torch.Size([768]) tensor(-0.2423)\n",
"torch.Size([768]) tensor(3.3407)\n",
"torch.Size([3072, 768]) tensor(3.8034)\n",
"torch.Size([3072]) tensor(-0.1843)\n",
"torch.Size([768, 3072]) tensor(-66.6718)\n",
"torch.Size([768]) tensor(0.3683)\n",
"torch.Size([768, 12, 64]) tensor(5.1000)\n",
"torch.Size([768, 12, 64]) tensor(0.0141)\n",
"torch.Size([768, 12, 64]) tensor(56.6268)\n",
"torch.Size([768, 12, 64]) tensor(-11.3588)\n",
"torch.Size([768, 12, 64]) tensor(2.9135)\n",
"torch.Size([12, 64]) tensor(-0.0876)\n",
"torch.Size([12, 64]) tensor(0.0180)\n",
"torch.Size([12, 64]) tensor(-0.1191)\n",
"torch.Size([2, 12, 64]) tensor(2.3190e-07)\n",
"torch.Size([768]) tensor(0.4160)\n",
"torch.Size([768]) tensor(7.0181)\n",
"torch.Size([768]) tensor(3.3831)\n",
"torch.Size([768]) tensor(7.6589)\n",
"torch.Size([3072, 768]) tensor(49.6100)\n",
"torch.Size([3072]) tensor(-2.2469)\n",
"torch.Size([768, 3072]) tensor(-122.5963)\n",
"torch.Size([768]) tensor(1.1283)\n",
"torch.Size([768, 12, 64]) tensor(-85.3010)\n",
"torch.Size([768, 12, 64]) tensor(-0.8522)\n",
"torch.Size([768, 12, 64]) tensor(-18.1076)\n",
"torch.Size([768, 12, 64]) tensor(-1.8181)\n",
"torch.Size([768, 12, 64]) tensor(-9.2780)\n",
"torch.Size([12, 64]) tensor(1.0340)\n",
"torch.Size([12, 64]) tensor(-0.0703)\n",
"torch.Size([12, 64]) tensor(1.4106)\n",
"torch.Size([2, 12, 64]) tensor(-1.0224e-07)\n",
"torch.Size([768]) tensor(0.1006)\n",
"torch.Size([768]) tensor(-1.4744)\n",
"torch.Size([768]) tensor(0.5111)\n",
"torch.Size([768]) tensor(1.4940)\n",
"torch.Size([3072, 768]) tensor(-10.1525)\n",
"torch.Size([3072]) tensor(1.4139)\n",
"torch.Size([768, 3072]) tensor(124.6283)\n",
"torch.Size([768]) tensor(-0.9184)\n",
"torch.Size([768, 12, 64]) tensor(-9.1619)\n",
"torch.Size([768, 12, 64]) tensor(-0.0258)\n",
"torch.Size([768, 12, 64]) tensor(31.2907)\n",
"torch.Size([768, 12, 64]) tensor(-11.1148)\n",
"torch.Size([768, 12, 64]) tensor(-20.2042)\n",
"torch.Size([12, 64]) tensor(0.0420)\n",
"torch.Size([12, 64]) tensor(0.0116)\n",
"torch.Size([12, 64]) tensor(0.3107)\n",
"torch.Size([2, 12, 64]) tensor(-5.8004e-08)\n",
"torch.Size([768]) tensor(-0.2560)\n",
"torch.Size([768]) tensor(-1.5868)\n",
"torch.Size([768]) tensor(-0.2003)\n",
"torch.Size([768]) tensor(-16.1038)\n",
"torch.Size([3072, 768]) tensor(-0.9454)\n",
"torch.Size([3072]) tensor(0.2846)\n",
"torch.Size([768, 3072]) tensor(-67.4690)\n",
"torch.Size([768]) tensor(0.9321)\n",
"torch.Size([768, 12, 64]) tensor(36.2474)\n",
"torch.Size([768, 12, 64]) tensor(0.0344)\n",
"torch.Size([768, 12, 64]) tensor(-63.7676)\n",
"torch.Size([768, 12, 64]) tensor(-9.4757)\n",
"torch.Size([768, 12, 64]) tensor(-5.0033)\n",
"torch.Size([12, 64]) tensor(-0.1341)\n",
"torch.Size([12, 64]) tensor(0.0031)\n",
"torch.Size([12, 64]) tensor(-0.4286)\n",
"torch.Size([2, 12, 64]) tensor(2.5408e-07)\n",
"torch.Size([768]) tensor(-0.0569)\n",
"torch.Size([768]) tensor(-7.6731)\n",
"torch.Size([768]) tensor(-1.9531)\n",
"torch.Size([768]) tensor(-3.7648)\n",
"torch.Size([3072, 768]) tensor(-16.2163)\n",
"torch.Size([3072]) tensor(2.6630)\n",
"torch.Size([768, 3072]) tensor(22.3108)\n",
"torch.Size([768]) tensor(-0.1288)\n",
"torch.Size([768, 12, 64]) tensor(26.5598)\n",
"torch.Size([768, 12, 64]) tensor(1.5946)\n",
"torch.Size([768, 12, 64]) tensor(34.9219)\n",
"torch.Size([768, 12, 64]) tensor(6.0831)\n",
"torch.Size([768, 12, 64]) tensor(-6.4807)\n",
"torch.Size([12, 64]) tensor(-0.0683)\n",
"torch.Size([12, 64]) tensor(-0.0270)\n",
"torch.Size([12, 64]) tensor(-0.1633)\n",
"torch.Size([2, 12, 64]) tensor(-3.3295e-08)\n",
"torch.Size([768]) tensor(-0.3243)\n",
"torch.Size([768]) tensor(0.3006)\n",
"torch.Size([768]) tensor(0.2705)\n",
"torch.Size([768]) tensor(0.6345)\n",
"torch.Size([3072, 768]) tensor(12.1707)\n",
"torch.Size([3072]) tensor(-1.2312)\n",
"torch.Size([768, 3072]) tensor(-180.4119)\n",
"torch.Size([768]) tensor(-0.6142)\n",
"torch.Size([768, 768]) tensor(67.9899)\n",
"torch.Size([768]) tensor(0.2034)\n",
"torch.Size([2, 768]) tensor(-1.5175e-05)\n",
"torch.Size([2]) tensor(0.)\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "sGzaejkAb265",
"colab_type": "text"
},
"source": [
"### 例2. 抽取式问答(类似[SQuAD](https://rajpurkar.github.io/SQuAD-explorer/))\n",
""
]
},
{
"cell_type": "code",
"metadata": {
"id": "yMUj6eqKb265",
"colab_type": "code",
"colab": {}
},
"source": [
"class AnsStartLogits(nn.Module):\n",
" \"\"\"\n",
" 用于预测每个token是否为答案span开始位置\n",
" \"\"\"\n",
" def __init__(self, hidden_size):\n",
" super().__init__()\n",
" self.linear = nn.Linear(hidden_size, 1)\n",
"\n",
" def forward(self, \n",
" hidden_states, \n",
" p_mask=None\n",
" ):\n",
" x = self.linear(hidden_states).squeeze(-1)\n",
"\n",
" if p_mask is not None:\n",
" x = x * (1 - p_mask) - 1e30 * p_mask\n",
" return x\n",
" \n",
" \n",
"class AnsEndLogits(nn.Module):\n",
" \"\"\"\n",
" 用于预测每个token是否为答案span结束位置,符合直觉,conditioned on 开始位置\n",
" \"\"\"\n",
" def __init__(self, hidden_size):\n",
" super().__init__()\n",
" self.layer = nn.Sequential(\n",
" nn.Linear(hidden_size * 2, hidden_size),\n",
" nn.Tanh(),\n",
" nn.LayerNorm(hidden_size),\n",
" nn.Linear(hidden_size, 1)\n",
" )\n",
"\n",
" def forward(self,\n",
" hidden_states,\n",
" start_states,\n",
" p_mask = None,\n",
" ):\n",
"\n",
" x = self.layer(torch.cat([hidden_states, start_states], dim=-1))\n",
" x = x.squeeze(-1)\n",
"\n",
" if p_mask is not None:\n",
" x = x * (1 - p_mask) - 1e30 * p_mask\n",
" return x\n",
" \n",
"\n",
"class XLNetQuestionAnswering(nn.Module):\n",
" \n",
" def __init__(self,\n",
" num_labels,\n",
" xlnet_model,\n",
" d_model=768,\n",
" top_k_start=2,\n",
" top_k_end=2\n",
" ):\n",
" super().__init__()\n",
" self.transformer = xlnet_model\n",
" self.start_logits = AnsStartLogits(d_model)\n",
" self.end_logits = AnsEndLogits(d_model)\n",
" self.top_k_start = top_k_start # for beam search\n",
" self.top_k_end = top_k_end # for beam search \n",
" \n",
" def forward(self, \n",
" model_inputs,\n",
" p_mask=None,\n",
" start_positions=None\n",
" ):\n",
" \"\"\"\n",
" p_mask:\n",
" 可选的mask, 被mask掉的位置不可能存在答案(e.g. [CLS], [PAD], ...)。\n",
" 1.0 表示应当被mask. 0.0反之。\n",
" start_positions:\n",
" 正确答案标注的开始位置。训练时需要输入模型以利用teacher forcing计算end_logits。\n",
" Inference时不需输入,beam search返回top k个开始和结束位置。\n",
" \"\"\"\n",
" transformer_outputs = self.transformer(**model_inputs)\n",
" \n",
" hidden_states = transformer_outputs[0]\n",
" start_logits = self.start_logits(hidden_states, p_mask=p_mask)\n",
" \n",
" if not start_positions is None:\n",
" # 在训练时利用 teacher forcing trick训练 end_logits\n",
" slen, hsz = hidden_states.shape[-2:]\n",
" start_positions = start_positions.expand(-1, -1, hsz) # shape (bsz, 1, hsz)\n",
" start_states = hidden_states.gather(-2, start_positions) # shape (bsz, 1, hsz)\n",
" start_states = start_states.expand(-1, slen, -1) # shape (bsz, slen, hsz)\n",
" end_logits = self.end_logits(hidden_states, \n",
" start_states=start_states, \n",
" p_mask=p_mask)\n",
" \n",
" return start_logits, end_logits\n",
" else:\n",
" # 在Inference时利用Beam Search求end_logits\n",
" bsz, slen, hsz = hidden_states.size()\n",
" start_probs = torch.softmax(start_logits, dim=-1) # shape (bsz, slen)\n",
"\n",
" start_top_probs, start_top_index = torch.topk(\n",
" start_probs, self.top_k_start, dim=-1\n",
" ) # shape (bsz, top_k_start)\n",
" start_top_index_exp = start_top_index.unsqueeze(-1).expand(-1, -1, hsz) # shape (bsz, top_k_start, hsz)\n",
" start_states = torch.gather(hidden_states, -2, start_top_index_exp) # shape (bsz, top_k_start, hsz)\n",
" start_states = start_states.unsqueeze(1).expand(-1, slen, -1, -1) # shape (bsz, slen, top_k_start, hsz)\n",
"\n",
" hidden_states_expanded = hidden_states.unsqueeze(2).expand_as(\n",
" start_states\n",
" ) # shape (bsz, slen, top_k_start, hsz)\n",
" p_mask = p_mask.unsqueeze(-1) if p_mask is not None else None\n",
" end_logits = self.end_logits(hidden_states_expanded, \n",
" start_states=start_states, \n",
" p_mask=p_mask) \n",
" end_probs = torch.softmax(end_logits, dim=1) # shape (bsz, slen, top_k_start)\n",
"\n",
" end_top_probs, end_top_index = torch.topk(\n",
" end_probs, self.top_k_end, dim=1\n",
" ) # shape (bsz, top_k_end, top_k_start)\n",
"\n",
" end_top_probs = torch.transpose(end_top_probs, 2, 1) # shape (bsz, top_k_start, top_k_end)\n",
" end_top_index = torch.transpose(end_top_index, 2, 1) # shape (bsz, top_k_start, top_k_end)\n",
"\n",
" end_top_probs = end_top_probs.reshape(-1, self.top_k_start * self.top_k_end)\n",
" end_top_index = end_top_index.reshape(-1, self.top_k_start * self.top_k_end)\n",
"\n",
" \n",
" return start_top_probs, start_top_index, end_top_probs, end_top_index, start_logits, end_logits\n",
" \n",
"def get_loss(criterion, \n",
" start_logits, \n",
" start_positions,\n",
" end_logits,\n",
" end_positions\n",
" ):\n",
" start_loss = criterion(start_logits, start_positions)\n",
" end_loss = criterion(end_logits, end_positions)\n",
" return (start_loss + end_loss) / 2\n",
" \n",
" \n"
],
"execution_count": 12,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "rOMx3Ls5V7Us",
"colab_type": "text"
},
"source": [
"### 检测用于训练的forward和backward"
]
},
{
"cell_type": "code",
"metadata": {
"id": "wgCYxpufb267",
"colab_type": "code",
"colab": {}
},
"source": [
"context = r\"\"\"\n",
" Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides general-purpose\n",
" architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural\n",
" Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between\n",
" TensorFlow 2.0 and PyTorch.\n",
" \"\"\"\n",
"questions = [\n",
" \"How many pretrained models are available in Transformers?\",\n",
" \"What does Transformers provide?\",\n",
" \"Transformers provides interoperability between which frameworks?\",\n",
"]\n",
"\n",
"start_positions = torch.LongTensor([95, 36, 110])\n",
"end_positions = torch.LongTensor([97, 88, 123])\n",
"p_mask = [[1]*12 + [0]* (125 -14) + [1,1],\n",
" [1]* 7 + [0]* (120 - 9) + [1,1],\n",
" [1]*12 + [0]* (125 -14) + [1,1],\n",
" ]\n",
"\n",
"neg_log_loss = nn.CrossEntropyLoss()\n",
"\n",
"q_answer = XLNetQuestionAnswering(2, model, 768, 2, 2)\n",
"\n",
"optimizer = torch.optim.AdamW(q_answer.parameters())"
],
"execution_count": 13,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "vjez3p3ox5ou",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 1000
},
"outputId": "58630274-11de-4cff-d1fa-dc3cb9551c69"
},
"source": [
"q_answer.train()\n",
"optimizer.zero_grad()\n",
"for ith, question in enumerate(questions):\n",
" start_logits, end_logits = q_answer(\n",
" tokenizer(question, \n",
" context, \n",
" add_special_tokens=True,\n",
" return_tensors='pt'),\n",
" p_mask=torch.ByteTensor(p_mask[ith]),\n",
" start_positions=start_positions[ith].view(1,1,1)\n",
" )\n",
" loss = get_loss(\n",
" criterion,\n",
" start_logits, \n",
" start_positions[ith].view(-1),\n",
" end_logits,\n",
" end_positions[ith].view(-1)\n",
" )\n",
" print(\"\\nTrue Start: {}, True End: {}\\nPred Start Prob: {}, Pred End Prob: {}\\nPred Max Start: {}, Pred Max End: {}\\nPred Max Start Prob: {}, Pred Max end Prob:{}\\nLoss: {}\\n\".format(\n",
" start_positions[ith].item(),\n",
" end_positions[ith].item(),\n",
" torch.sigmoid(start_logits[:,start_positions[ith]]).item(), \n",
" torch.sigmoid(end_logits[:, end_positions[ith]]).item(),\n",
" torch.argmax(start_logits).item(),\n",
" torch.argmax(end_logits).item(),\n",
" torch.sigmoid(torch.max(start_logits)).item(), \n",
" torch.sigmoid(torch.max(end_logits)).item(),\n",
" loss.item()\n",
" )\n",
" )\n",
" print(\"=\"*25)\n",
" loss.backward()\n",
" optimizer.step()\n",
"\n",
"print(\"\\nConfirm that the gradients are computed for the original XLNet parameters.\")\n",
"for param in q_answer.parameters():\n",
" print(param.shape, param.grad.sum() if not param.grad is None else param.grad)"
],
"execution_count": 14,
"outputs": [
{
"output_type": "stream",
"text": [
"\n",
"True Start: 95, True End: 97\n",
"Pred Start Prob: 0.3128710687160492, Pred End Prob: 0.6340706944465637\n",
"Pred Max Start: 78, Pred Max End: 39\n",
"Pred Max Start Prob: 0.6634821891784668, Pred Max end Prob:0.6745399832725525\n",
"Loss: 4.699392318725586\n",
"\n",
"=========================\n",
"\n",
"True Start: 36, True End: 88\n",
"Pred Start Prob: 0.6726937294006348, Pred End Prob: 0.93719482421875\n",
"Pred Max Start: 25, Pred Max End: 96\n",
"Pred Max Start Prob: 0.8701046705245972, Pred Max end Prob:0.9859831929206848\n",
"Loss: 5.206717491149902\n",
"\n",
"=========================\n",
"\n",
"True Start: 110, True End: 123\n",
"Pred Start Prob: 0.8552238941192627, Pred End Prob: 0.0\n",
"Pred Max Start: 97, Pred Max End: 98\n",
"Pred Max Start Prob: 0.9279953241348267, Pred Max end Prob:0.4768109917640686\n",
"Loss: 5.000000075237331e+29\n",
"\n",
"=========================\n",
"\n",
"Confirm that the gradients are computed for the original XLNet parameters.\n",
"torch.Size([1, 1, 768]) None\n",
"torch.Size([32000, 768]) tensor(-0.6884)\n",
"torch.Size([768, 12, 64]) tensor(-0.0334)\n",
"torch.Size([768, 12, 64]) tensor(0.0020)\n",
"torch.Size([768, 12, 64]) tensor(-0.2530)\n",
"torch.Size([768, 12, 64]) tensor(0.1670)\n",
"torch.Size([768, 12, 64]) tensor(-0.3664)\n",
"torch.Size([12, 64]) tensor(0.0001)\n",
"torch.Size([12, 64]) tensor(-0.0014)\n",
"torch.Size([12, 64]) tensor(0.0102)\n",
"torch.Size([2, 12, 64]) tensor(-9.2882e-10)\n",
"torch.Size([768]) tensor(-0.0579)\n",
"torch.Size([768]) tensor(-0.0086)\n",
"torch.Size([768]) tensor(0.3276)\n",
"torch.Size([768]) tensor(-0.4108)\n",
"torch.Size([3072, 768]) tensor(-0.7222)\n",
"torch.Size([3072]) tensor(0.0196)\n",
"torch.Size([768, 3072]) tensor(1.9823)\n",
"torch.Size([768]) tensor(-0.0305)\n",
"torch.Size([768, 12, 64]) tensor(0.1537)\n",
"torch.Size([768, 12, 64]) tensor(0.1984)\n",
"torch.Size([768, 12, 64]) tensor(-0.1475)\n",
"torch.Size([768, 12, 64]) tensor(-0.3304)\n",
"torch.Size([768, 12, 64]) tensor(-0.3685)\n",
"torch.Size([12, 64]) tensor(-0.0085)\n",
"torch.Size([12, 64]) tensor(-9.0756e-05)\n",
"torch.Size([12, 64]) tensor(0.0146)\n",
"torch.Size([2, 12, 64]) tensor(-6.3806e-09)\n",
"torch.Size([768]) tensor(-0.0117)\n",
"torch.Size([768]) tensor(0.0255)\n",
"torch.Size([768]) tensor(0.0031)\n",
"torch.Size([768]) tensor(-0.4477)\n",
"torch.Size([3072, 768]) tensor(-0.6170)\n",
"torch.Size([3072]) tensor(-0.0502)\n",
"torch.Size([768, 3072]) tensor(-0.3674)\n",
"torch.Size([768]) tensor(0.0046)\n",
"torch.Size([768, 12, 64]) tensor(0.1544)\n",
"torch.Size([768, 12, 64]) tensor(0.0277)\n",
"torch.Size([768, 12, 64]) tensor(-0.7144)\n",
"torch.Size([768, 12, 64]) tensor(0.0200)\n",
"torch.Size([768, 12, 64]) tensor(2.8775)\n",
"torch.Size([12, 64]) tensor(-0.0066)\n",
"torch.Size([12, 64]) tensor(-0.0012)\n",
"torch.Size([12, 64]) tensor(-0.0104)\n",
"torch.Size([2, 12, 64]) tensor(5.9663e-09)\n",
"torch.Size([768]) tensor(0.0509)\n",
"torch.Size([768]) tensor(-0.0095)\n",
"torch.Size([768]) tensor(-0.0630)\n",
"torch.Size([768]) tensor(0.0002)\n",
"torch.Size([3072, 768]) tensor(0.3525)\n",
"torch.Size([3072]) tensor(0.0530)\n",
"torch.Size([768, 3072]) tensor(2.0844)\n",
"torch.Size([768]) tensor(-0.0176)\n",
"torch.Size([768, 12, 64]) tensor(0.2019)\n",
"torch.Size([768, 12, 64]) tensor(0.2833)\n",
"torch.Size([768, 12, 64]) tensor(0.6085)\n",
"torch.Size([768, 12, 64]) tensor(-0.1063)\n",
"torch.Size([768, 12, 64]) tensor(-0.7396)\n",
"torch.Size([12, 64]) tensor(0.0198)\n",
"torch.Size([12, 64]) tensor(-0.0023)\n",
"torch.Size([12, 64]) tensor(-0.0082)\n",
"torch.Size([2, 12, 64]) tensor(-2.4584e-09)\n",
"torch.Size([768]) tensor(-0.2631)\n",
"torch.Size([768]) tensor(-0.0389)\n",
"torch.Size([768]) tensor(0.0537)\n",
"torch.Size([768]) tensor(0.2082)\n",
"torch.Size([3072, 768]) tensor(5.2597)\n",
"torch.Size([3072]) tensor(-0.2162)\n",
"torch.Size([768, 3072]) tensor(1.0177)\n",
"torch.Size([768]) tensor(-0.0024)\n",
"torch.Size([768, 12, 64]) tensor(0.2092)\n",
"torch.Size([768, 12, 64]) tensor(-0.0467)\n",
"torch.Size([768, 12, 64]) tensor(2.2503)\n",
"torch.Size([768, 12, 64]) tensor(0.3033)\n",
"torch.Size([768, 12, 64]) tensor(-1.2354)\n",
"torch.Size([12, 64]) tensor(-0.0038)\n",
"torch.Size([12, 64]) tensor(-0.0013)\n",
"torch.Size([12, 64]) tensor(0.0100)\n",
"torch.Size([2, 12, 64]) tensor(5.4883e-09)\n",
"torch.Size([768]) tensor(-0.1086)\n",
"torch.Size([768]) tensor(0.0420)\n",
"torch.Size([768]) tensor(0.1451)\n",
"torch.Size([768]) tensor(0.3843)\n",
"torch.Size([3072, 768]) tensor(1.1731)\n",
"torch.Size([3072]) tensor(-0.0912)\n",
"torch.Size([768, 3072]) tensor(-0.0175)\n",
"torch.Size([768]) tensor(0.0038)\n",
"torch.Size([768, 12, 64]) tensor(-0.1283)\n",
"torch.Size([768, 12, 64]) tensor(0.0159)\n",
"torch.Size([768, 12, 64]) tensor(1.8471)\n",
"torch.Size([768, 12, 64]) tensor(-0.0603)\n",
"torch.Size([768, 12, 64]) tensor(-0.5668)\n",
"torch.Size([12, 64]) tensor(-0.0011)\n",
"torch.Size([12, 64]) tensor(0.0008)\n",
"torch.Size([12, 64]) tensor(0.0101)\n",
"torch.Size([2, 12, 64]) tensor(1.6712e-09)\n",
"torch.Size([768]) tensor(0.2400)\n",
"torch.Size([768]) tensor(-0.0586)\n",
"torch.Size([768]) tensor(0.0619)\n",
"torch.Size([768]) tensor(-0.2086)\n",
"torch.Size([3072, 768]) tensor(1.8524)\n",
"torch.Size([3072]) tensor(-0.1007)\n",
"torch.Size([768, 3072]) tensor(1.4429)\n",
"torch.Size([768]) tensor(-0.0088)\n",
"torch.Size([768, 12, 64]) tensor(0.5602)\n",
"torch.Size([768, 12, 64]) tensor(-0.0269)\n",
"torch.Size([768, 12, 64]) tensor(12.1219)\n",
"torch.Size([768, 12, 64]) tensor(-0.5672)\n",
"torch.Size([768, 12, 64]) tensor(-1.1886)\n",
"torch.Size([12, 64]) tensor(-0.0125)\n",
"torch.Size([12, 64]) tensor(-0.0005)\n",
"torch.Size([12, 64]) tensor(-0.0047)\n",
"torch.Size([2, 12, 64]) tensor(8.1666e-09)\n",
"torch.Size([768]) tensor(0.3063)\n",
"torch.Size([768]) tensor(-0.0601)\n",
"torch.Size([768]) tensor(0.0642)\n",
"torch.Size([768]) tensor(-1.2854)\n",
"torch.Size([3072, 768]) tensor(0.6916)\n",
"torch.Size([3072]) tensor(0.0861)\n",
"torch.Size([768, 3072]) tensor(-5.8404)\n",
"torch.Size([768]) tensor(-0.0209)\n",
"torch.Size([768, 12, 64]) tensor(-0.2547)\n",
"torch.Size([768, 12, 64]) tensor(0.0448)\n",
"torch.Size([768, 12, 64]) tensor(-11.1511)\n",
"torch.Size([768, 12, 64]) tensor(-0.9826)\n",
"torch.Size([768, 12, 64]) tensor(-4.3894)\n",
"torch.Size([12, 64]) tensor(-0.0002)\n",
"torch.Size([12, 64]) tensor(0.0011)\n",
"torch.Size([12, 64]) tensor(0.0086)\n",
"torch.Size([2, 12, 64]) tensor(1.4228e-08)\n",
"torch.Size([768]) tensor(0.3623)\n",
"torch.Size([768]) tensor(0.4062)\n",
"torch.Size([768]) tensor(-0.1065)\n",
"torch.Size([768]) tensor(-3.0040)\n",
"torch.Size([3072, 768]) tensor(5.2218)\n",
"torch.Size([3072]) tensor(-0.2266)\n",
"torch.Size([768, 3072]) tensor(9.2306)\n",
"torch.Size([768]) tensor(0.0284)\n",
"torch.Size([768, 12, 64]) tensor(-0.4832)\n",
"torch.Size([768, 12, 64]) tensor(0.0096)\n",
"torch.Size([768, 12, 64]) tensor(-10.0414)\n",
"torch.Size([768, 12, 64]) tensor(0.5542)\n",
"torch.Size([768, 12, 64]) tensor(-1.1537)\n",
"torch.Size([12, 64]) tensor(0.0121)\n",
"torch.Size([12, 64]) tensor(-0.0002)\n",
"torch.Size([12, 64]) tensor(0.0021)\n",
"torch.Size([2, 12, 64]) tensor(1.1473e-08)\n",
"torch.Size([768]) tensor(0.1046)\n",
"torch.Size([768]) tensor(-0.5176)\n",
"torch.Size([768]) tensor(-0.1872)\n",
"torch.Size([768]) tensor(-0.4094)\n",
"torch.Size([3072, 768]) tensor(-2.1765)\n",
"torch.Size([3072]) tensor(0.2907)\n",
"torch.Size([768, 3072]) tensor(-17.4914)\n",
"torch.Size([768]) tensor(-0.2188)\n",
"torch.Size([768, 12, 64]) tensor(0.1278)\n",
"torch.Size([768, 12, 64]) tensor(0.0075)\n",
"torch.Size([768, 12, 64]) tensor(4.4422)\n",
"torch.Size([768, 12, 64]) tensor(0.1824)\n",
"torch.Size([768, 12, 64]) tensor(-0.2453)\n",
"torch.Size([12, 64]) tensor(-0.0021)\n",
"torch.Size([12, 64]) tensor(0.0010)\n",
"torch.Size([12, 64]) tensor(-0.0038)\n",
"torch.Size([2, 12, 64]) tensor(3.8835e-08)\n",
"torch.Size([768]) tensor(0.0947)\n",
"torch.Size([768]) tensor(-0.1559)\n",
"torch.Size([768]) tensor(-0.4608)\n",
"torch.Size([768]) tensor(-3.1537)\n",
"torch.Size([3072, 768]) tensor(-0.0686)\n",
"torch.Size([3072]) tensor(-0.1366)\n",
"torch.Size([768, 3072]) tensor(-23.9523)\n",
"torch.Size([768]) tensor(-0.0108)\n",
"torch.Size([768, 12, 64]) tensor(-1.3291)\n",
"torch.Size([768, 12, 64]) tensor(0.0523)\n",
"torch.Size([768, 12, 64]) tensor(-1.8151)\n",
"torch.Size([768, 12, 64]) tensor(-0.4039)\n",
"torch.Size([768, 12, 64]) tensor(-0.0539)\n",
"torch.Size([12, 64]) tensor(0.0087)\n",
"torch.Size([12, 64]) tensor(-0.0025)\n",
"torch.Size([12, 64]) tensor(0.0149)\n",
"torch.Size([2, 12, 64]) tensor(-7.3160e-09)\n",
"torch.Size([768]) tensor(-0.4885)\n",
"torch.Size([768]) tensor(1.7355)\n",
"torch.Size([768]) tensor(-0.3012)\n",
"torch.Size([768]) tensor(1.5989)\n",
"torch.Size([3072, 768]) tensor(10.9814)\n",
"torch.Size([3072]) tensor(-1.0466)\n",
"torch.Size([768, 3072]) tensor(7.2909)\n",
"torch.Size([768]) tensor(0.0650)\n",
"torch.Size([768, 12, 64]) tensor(4.3189)\n",
"torch.Size([768, 12, 64]) tensor(-0.3560)\n",
"torch.Size([768, 12, 64]) tensor(36.1090)\n",
"torch.Size([768, 12, 64]) tensor(-2.3517)\n",
"torch.Size([768, 12, 64]) tensor(-2.1882)\n",
"torch.Size([12, 64]) tensor(0.0060)\n",
"torch.Size([12, 64]) tensor(-0.0008)\n",
"torch.Size([12, 64]) tensor(-0.0341)\n",
"torch.Size([2, 12, 64]) tensor(4.8329e-08)\n",
"torch.Size([768]) tensor(11.1667)\n",
"torch.Size([768]) tensor(17.8769)\n",
"torch.Size([768]) tensor(0.2330)\n",
"torch.Size([768]) tensor(-0.1388)\n",
"torch.Size([3072, 768]) tensor(20.5294)\n",
"torch.Size([3072]) tensor(-1.7453)\n",
"torch.Size([768, 3072]) tensor(-39.9618)\n",
"torch.Size([768]) tensor(0.1220)\n",
"torch.Size([1, 768]) tensor(-10.1781)\n",
"torch.Size([1]) tensor(9.1270e-08)\n",
"torch.Size([768, 1536]) tensor(64.5171)\n",
"torch.Size([768]) tensor(-0.1971)\n",
"torch.Size([768]) tensor(0.1439)\n",
"torch.Size([768]) tensor(-0.2693)\n",
"torch.Size([1, 768]) tensor(0.0336)\n",
"torch.Size([1]) tensor(0.5000)\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "urqElauRWKyF",
"colab_type": "text"
},
"source": [
"### inference的forward以及实现Beam Search decoding"
]
},
{
"cell_type": "code",
"metadata": {
"id": "qJ-9DxmHHAsS",
"colab_type": "code",
"colab": {}
},
"source": [
"import numpy as np\n",
"def decode(start_probs, end_probs, topk):\n",
" \"\"\"\n",
" 给定beam中预测的开始和结束概率,搜索topk个最佳答案\n",
" \"\"\"\n",
" top_k_start = start_probs.shape[-1]\n",
" top_k_end = end_probs.shape[-1] // top_k_start\n",
"\n",
" # 计算每一个(start, end)对的分数 P(start, end| sentence) = P(start|sentence) * P(end|start, sentence)\n",
" joint_probs = dict()\n",
" for i in range(top_k_start):\n",
" for j in range(top_k_end):\n",
" end_idx = i*top_k_end+j\n",
" joint_probs[(i, end_idx)] = start_probs[i]*end_probs[end_idx]\n",
" \n",
" id_pairs, probs = zip(*sorted(joint_probs.items(), key=lambda kv:kv[1], reverse=True)[:topk])\n",
" start_ids, end_ids = zip(*id_pairs)\n",
" return start_ids, end_ids, probs\n"
],
"execution_count": 15,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "SXzlKiGKb269",
"colab_type": "code",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 370
},
"outputId": "1c4293cb-0a81-4f27-bc4a-c8330be38bf8"
},
"source": [
"# inference\n",
"context = r\"\"\"\n",
" Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides general-purpose\n",
" architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural\n",
" Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between\n",
" TensorFlow 2.0 and PyTorch.\n",
" \"\"\"\n",
"questions = [\n",
" \"How many pretrained models are available in Transformers?\",\n",
" \"What does Transformers provide?\",\n",
" \"Transformers provides interoperability between which frameworks?\",\n",
"]\n",
"q_answer.eval()\n",
"for ith, question in enumerate(questions):\n",
" inputs = tokenizer(question, context, add_special_tokens=True, return_tensors=\"pt\")\n",
" input_ids = inputs[\"input_ids\"].tolist()[0]\n",
" \n",
" text_tokens = tokenizer.convert_ids_to_tokens(input_ids)\n",
" start_probs, start_index, end_probs, end_index, stt_logits, end_logits = q_answer(\n",
" inputs, \n",
" p_mask=torch.ByteTensor(p_mask[ith])\n",
" )\n",
"\n",
" pred_starts, pred_ends, probs = decode(\n",
" start_probs.detach().squeeze().numpy(), \n",
" end_probs.detach().squeeze().numpy(), \n",
" 2)\n",
" \n",
" # 只打印一个答案\n",
" start = start_index[:, pred_starts[0]].item()\n",
" end = end_index[:, pred_ends[0]].item()\n",
" \n",
"# print(probs, pred_starts, pred_ends)\n",
"# print(len(input_ids), stt_logits.shape, end_logits.shape)\n",
"# print(tokenizer.convert_ids_to_tokens(input_ids).index('?'))\n",
"\n",
" print(\"=\"*25)\n",
" print(\"True start: {}, True end: {}\".format(\n",
" start_positions[ith].item(),\n",
" end_positions[ith].item()\n",
" ))\n",
" print(\"Max answer prob: {:0.8f}, start idx: {}, end idx: {}\".format(\n",
" probs[0],\n",
" start,\n",
" end,\n",
" ))\n",
" print(\"-\"*25)\n",
" print(\"Question: '{}'\".format(question))\n",
" print(\"Answer: '{}'\".format(tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[start:end]))))\n",
" print(\"=\"*25)"
],
"execution_count": 16,
"outputs": [
{
"output_type": "stream",
"text": [
"=========================\n",
"True start: 95, True end: 97\n",
"Max answer prob: 0.00008122, start idx: 120, end idx: 122\n",
"-------------------------\n",
"Question: 'How many pretrained models are available in Transformers?'\n",
"Answer: 'orch'\n",
"=========================\n",
"=========================\n",
"True start: 36, True end: 88\n",
"Max answer prob: 0.00008121, start idx: 115, end idx: 117\n",
"-------------------------\n",
"Question: 'What does Transformers provide?'\n",
"Answer: 'orch'\n",
"=========================\n",
"=========================\n",
"True start: 110, True end: 123\n",
"Max answer prob: 0.00008122, start idx: 120, end idx: 122\n",
"-------------------------\n",
"Question: 'Transformers provides interoperability between which frameworks?'\n",
"Answer: 'orch'\n",
"=========================\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "code",
"metadata": {
"id": "BwYZU9c4b26-",
"colab_type": "code",
"colab": {}
},
"source": [
""
],
"execution_count": 16,
"outputs": []
}
]
}